Modeling Wait Times
5.4. Modeling Wait Times#
We are interested in modeling the experience of someone waiting at a bus stop. We could develop a complex model that involves the intervals between scheduled arrivals, the bus line, and direction. Instead, we take a simpler approach and narrow the focus to one line, one direction, and one scheduled interval. We examine the northbound C line stops that are scheduled to arrive 12 minutes apart:
bus_c_n_12 = bus_c_n[bus_c_n['sched_inter'] == 12]
Both the complex and the narrow approaches are legitimate, but we do not yet have the tools to approach the complex model (see Chapter 15 for more details on modeling).
So far, we have examined the distribution of the number of minutes the bus is late. We create another histogram of this delay for the subset of data that we are analyzing (northbound C line stops that are scheduled to arrive 12 minutes after the previous bus):
fig = px.histogram(bus_c_n_12, x='minutes_late',
labels={'minutes_late':'Minutes late'},
nbins=120, width=450, height=300)
fig.add_annotation(x=20, y=150, showarrow=False,
text="Line C, northbound<br>Scheduled arrivals: 12 minutes apart" )
fig.update_xaxes(range=[-13, 40])
fig.show()

And let’s calculate the minimum, maximum, and median lateness:
print(f"smallest amount late: {np.min(bus_c_n_12['minutes_late']):.2f} minutes\n",
f"greatest amount late: {np.max(bus_c_n_12['minutes_late']):.2f} minutes\n",
f"median amount late: {np.median(bus_c_n_12['minutes_late']):.2f} minutes\n")
smallest amount late: -10.20 minutes
greatest amount late: 57.00 minutes
median amount late: -0.50 minutes
Interestingly, the northbound buses on the C line that are 12 minutes apart are more often early than not!
Now let’s revisit our question to confirm that we are on track for answering it. A summary of how late the buses are does not quite address the experience of the person waiting for the bus. When someone arrives at a bus stop, they need to wait for the next bus to arrive. Figure 5.1 shows an idealization of time passing as passengers and buses arrive at the bus stop. If people are arriving at the bus stop at random times, notice that they are more likely to arrive in a time interval where the bus is delayed because there’s a longer interval between buses. This arrival pattern is an example of size-biased sampling. So to answer the question of what do people experience when waiting for a bus, we need to do more than summarize how late the bus is.
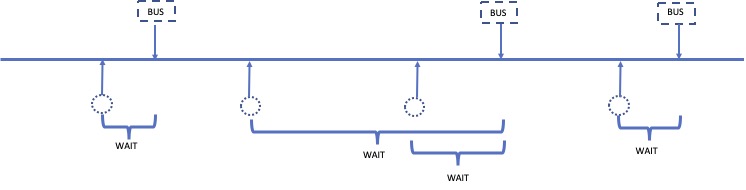
Fig. 5.1 Idealized timeline with buses arriving (rectangles), passengers arriving (circles), and time the rider waits for the next bus to arrive (curly brackets).#
We can design a simulation that mimics waiting for a bus over the course of one day, using the ideas from Chapter 3. To do this, we set up a string of scheduled bus arrivals that are 12 minutes apart from 6 a.m. to midnight:
scheduled = 12 * np.arange(91)
scheduled
array([ 0, 12, 24, ..., 1056, 1068, 1080])
Then, for each scheduled arrival, we simulate its actual arrival time by adding a random number of minutes each bus is late. To do this, we choose the minutes late from the distribution of observed lateness of the actual buses. Notice how we have incorporated the real data in our simulation study by using the distribution of actual delays of the buses that are 12 minutes apart:
minutes_late = bus_c_n_12['minutes_late']
actual = scheduled + np.random.choice(minutes_late, size=91, replace=True)
We need to sort these arrival times because when a bus is super late, another may well come along before it:
actual.sort()
actual
array([ -1.2 , 25.37, 32.2 , ..., 1051.02, 1077. , 1089.43])
We also need to simulate the arrival of people at the bus stop at random times throughout the day. We can use another, different urn model for the passenger arrivals. For the passengers, we put a marble in the urn with a time on it. These run from time 0, which stands for 6 a.m., to the arrival of the last bus at midnight, which is 1,068 minutes past 6 a.m… To match the way the bus times are measured in our data, we make the times 1/100 of a minute apart:
pass_arrival_times = np.arange(100*1068)
pass_arrival_times / 100
array([ 0. , 0.01, 0.02, ..., 1067.97, 1067.98, 1067.99])
Now we can simulate the arrival of, say, five hundred people at the bus stop throughout the day. We draw five hundred times from this urn, replacing the marbles between draws:
sim_arrival_times = (
np.random.choice(pass_arrival_times, size=500, replace=True) / 100
)
sim_arrival_times.sort()
sim_arrival_times
array([ 2.06, 3.01, 8.54, ..., 1064. , 1064.77, 1066.42])
To find out how long each individual waits, we look for the soonest bus to arrive after their sampled time. The difference between these two times (the sampled time of the person and the soonest bus arrival after that) is how long the person waits:
i = np.searchsorted(actual, sim_arrival_times, side='right')
sim_wait_times = actual[i] - sim_arrival_times
sim_wait_times
array([23.31, 22.36, 16.83, ..., 13. , 12.23, 10.58])
We can set up a complete simulation where we simulate, say, 200 days of bus arrivals, and for each day, we simulate 500 people arriving at the bus stop at random times throughout the day. In total, that’s 100,000 simulated wait times:
sim_wait_times = []
for day in np.arange(0, 200, 1):
bus_late = np.random.choice(minutes_late, size=91, replace=True)
actual = scheduled + bus_late
actual.sort()
sim_arrival_times = (
np.random.choice(pass_arrival_times, size=500, replace=True) / 100
)
sim_arrival_times.sort()
i = np.searchsorted(actual, sim_arrival_times, side="right")
sim_wait_times = np.append(sim_wait_times, actual[i] - sim_arrival_times)
Let’s make a histogram of these simulated wait times to examine the distribution:
fig = px.histogram(x=sim_wait_times, nbins=40,
histnorm='probability density',
width=450, height=300)
fig.update_xaxes(title="Simulated wait times for 100,000 passengers")
fig.update_yaxes(title="proportion")
fig.show()

As we expect, we find a skewed distribution. We can model this by a constant where we use absolute loss to select the best constant. We saw in Chapter 4 that absolute loss gives us the median wait time:
print(f"Median wait time: {np.median(sim_wait_times):.2f} minutes")
Median wait time: 6.49 minutes
The median of about six and a half minutes doesn’t seem too long. While our model captures the typical wait time, we also want to provide an estimate of the variability in the process. This topic is covered in Chapter 17. We can compute the upper quartile of wait times to give us a sense of variability:
print(f"Upper quartile: {np.quantile(sim_wait_times, 0.75):.2f} minutes")
Upper quartile: 10.62 minutes
The upper quartile is quite large. It’s undoubtedly memorable when you have to wait more than 10 minutes for a bus that is supposed to arrive every 12 minutes, and this happens one in four times you take the bus!