HTTP
14.3. HTTP#
HTTP (aka HyperText Transfer Protocol) is an all-purpose infrastructure to access resources on the web. There are a tremendous number of datasets available to us on the internet, and with HTTP we can acquire these datasets.
The internet allows computers to communicate with each other, and HTTP places a structure on the communication. HTTP is a simple request-response protocol, where a client submits a request to a server in a specially formatted text message, and the server sends a specially formatted text response back. The client might be a web browser or our Python session.
An HTTP request has two parts: a header and an optional body. The header must follow a specific syntax. An example request to obtain the Wikipedia page shown in Figure 14.3 looks like the following
GET /wiki/1500_metres_world_record_progression HTTP/1.1
Host: en.wikipedia.org
User-Agent: curl/7.65.2
Accept: */*
{blank_line}
The first line contains three pieces of information: it starts with the method of the request, which is GET; this is followed by the URL of the web page we want; and last is the protocol and version. Each of the three lines that follow give auxiliary information for the server. This information has the format name: value. Finally, a blank line marks the end of the header. Note that we’ve marked the blank line with {blank_line} in the preceding snippet; in the actual message, this is actually a blank line.
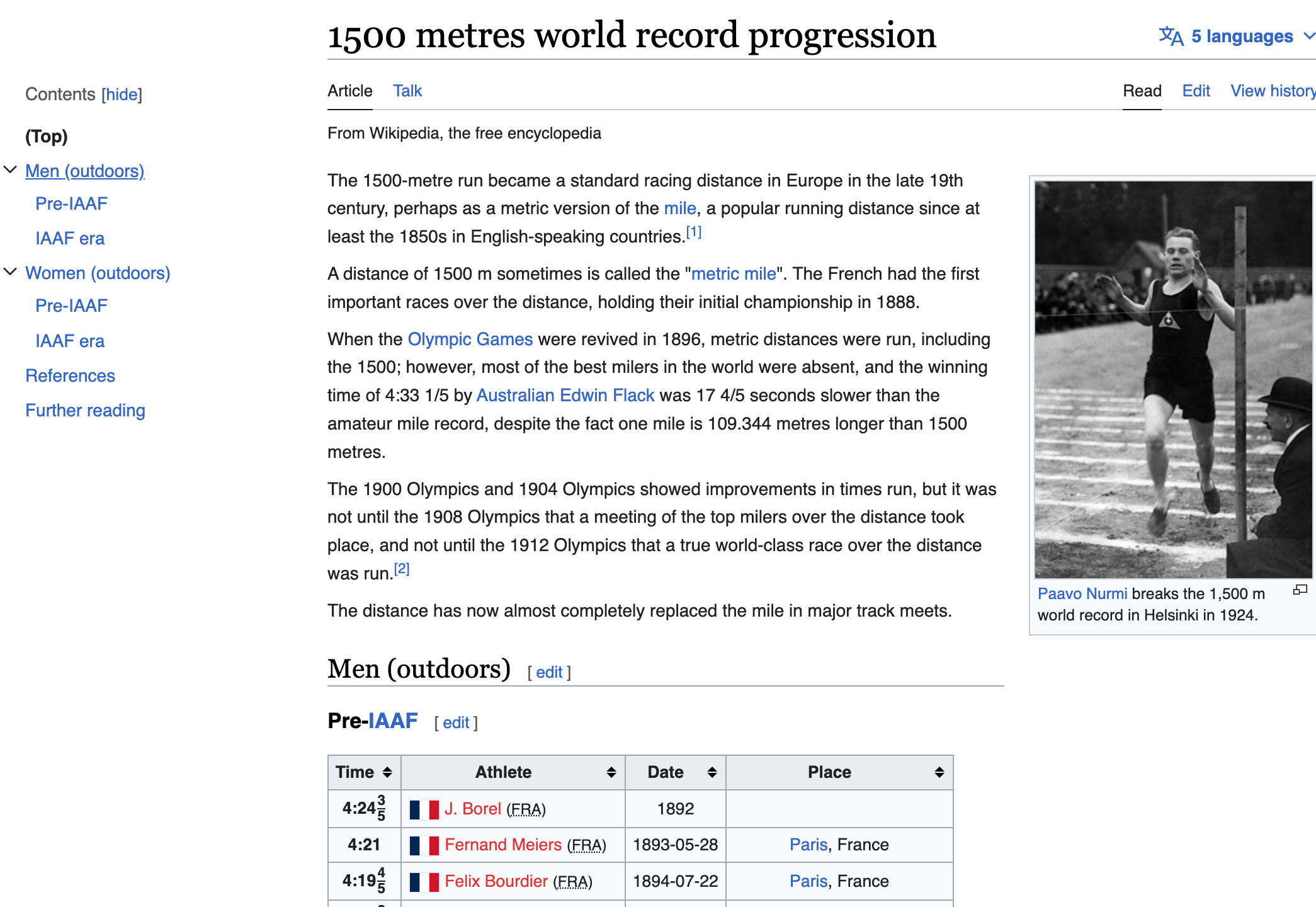
Fig. 14.3 Screenshot of the Wikipedia page with data on the world record for the 1,500-meter race#
The client’s computer sends this message over the internet to the Wikipedia server. The server processes the request and sends a response, which also consists of a header and body. The header for the response looks like this:
< HTTP/1.1 200 OK
< date: Fri, 24 Feb 2023 00:11:49 GMT
< server: mw1369.eqiad.wmnet
< x-content-type-options: nosniff
< content-language: en
< vary: Accept-Encoding,Cookie,Authorization
< last-modified: Tue, 21 Feb 2023 15:00:46 GMT
< content-type: text/html; charset=UTF-8
...
< content-length: 153912
{blank_line}
The first line states that the request completed successfully; the status code is 200. The next lines give additional information for the client. We shortened this header quite a bit to focus on just a few pieces of information that tell us the content of the body is HTML and uses UTF-8 encoding, and the content is 153,912 characters long. Finally, the blank line at the end of the header tells the client that the server has finished sending header information, and the response body follows.
HTTP is used in almost every application that interacts with the internet. For example, if you visit this same Wikipedia page in your web browser, the browser makes the same basic HTTP request as the one just shown. When it receives the response, it displays the body in your browser’s window, which looks like the screenshot in Figure 14.3.
In practice, we do not write out full HTTP requests ourselves. Instead, we use tools like the requests Python library to construct requests for us. The following code constructs the HTTP request for the page in Figure 14.3 for us. We simply pass the URL to requests.get. The “get” in the name indicates the GET method is being used:
import requests
url_1500 = 'https://en.wikipedia.org/wiki/1500_metres_world_record_progression'
resp_1500 = requests.get(url_1500)
We can check the status of our request to make sure the server completed it successfully:
resp_1500.status_code
200
We can thoroughly examine the request and response through the object’s attributes. As an example, let’s take a look at the key-value pairs in the header in our request:
for key in resp_1500.request.headers:
print(f'{key}: {resp_1500.request.headers[key]}')
User-Agent: python-requests/2.25.1
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-alive
Although we did not specify any header information in our function call, request.get provided some basic information for us. If we need to send special header information, we can specify them in our call.
Now let’s examine the header of the response we received from the server:
len(resp_1500.headers)
20
As we saw earlier, there’s a lot of header information in the response. We just display the date, content-type, and content-length:
keys = ['date', 'content-type', 'content-length' ]
for key in keys:
print(f'{key}: {resp_1500.headers[key]}')
date: Fri, 10 Mar 2023 01:54:13 GMT
content-type: text/html; charset=UTF-8
content-length: 23064
Finally, we display the first several hundred characters of the response body (the entire content is too long to display nicely here):
resp_1500.text[:600]
'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled" lang="en" dir="ltr">\n<head>\n<meta charset="UTF-8"/>\n<title>1500 metres world record progression - Wikipedia</title>\n<script>document.documentE'
We confirm that the response is an HTML document and that it contains the title 1500 metres world record progression - Wikipedia. We have successfully retrieved the web page shown in Figure 14.3.
Our HTTP request has been successful, and the server has returned a status code of 200. There are hundreds of other HTTP status codes. Thankfully, they are grouped into categories to make them easier to remember (see Table 14.1).
Code |
Type |
Description |
|---|---|---|
100s |
Informational |
More input is expected from the client or server (100 Continue, 102 Processing, etc.). |
200s |
Success |
The client’s request was successful (200 OK, 202 Accepted, etc.). |
300s |
The redirection |
Requested URL is located elsewhere and may need user’s further action from the user (300 Multiple Choices, 301 Moved Permanently, etc.). |
400s |
Client error |
A client-side error occurred(400 Bad Request, 403 Forbidden, 404 Not Found, etc.). |
500s |
Server error |
A server-side error occurred or the server is incapable of performing the request (500 Internal Server Error, 503 Service Unavailable, etc.). |
One common error code that might look familiar is 404, which tells us we have requested a resource that doesn’t exist. We send such a request here:
url = "https://www.youtube.com/404errorwow"
bad_loc = requests.get(url)
bad_loc.status_code
404
The request we made to retrieve the web page was a GET HTTP request. There are four main HTTP request types: GET, POST, PUT, and DELETE. The two most commonly used methods are GET and POST. We just used GET to retrieve the web page:
resp_1500.request.method
'GET'
The POST request is used to send specific information from the client to the server. In the next section, we use POST to retrieve data from Spotify.