JSON Data
14.2. JSON Data#
JavaScript Object Notation (JSON) is a popular format for exchanging data on the web. This plain-text format has a simple and flexible syntax that aligns well with Python dictionaries, and it is easy for machines to parse and people to read.
Briefly, JSON has two main structures, the object and the array:
- Object
Like a Python
dict, a JSON object is an unordered collection of name-value pairs. These pairs are contained in curly braces; each is formatted as"name":value, and separated by commas.- Array
Like a Python
list, a JSON array is an ordered collection of values contained in square brackets, where the values are unnamed and separated by commas.
The values in an object and array can be of different types and can be nested. That is, an array can contain objects and vice versa. The primitive types are limited to string in double quotes; number in text representation; logical as true or false; and null.
The following short JSON file demonstrates all of these syntactical features:
{"lender_id":"matt",
"loan_count":23,
"status":[2, 1, 3],
"sponsored": false,
"sponsor_name": null,
"lender_dem":{"sex":"m","age":77 }
}
Here we have an object that contains six name-value pairs. The values are heterogeneous; four are primitive values: string, number, logical, and null. The status value consists of an array of three (ordered) numbers,
and lender_dem is an object with demographic information.
The built-in json package can be used to work with JSON files in Python. For example, we can load this small file into a Python dictionary:
import json
from pathlib import Path
file_path = Path() / 'data' / 'js_ex' / 'ex.json'
ex_dict = json.load(open(file_path))
ex_dict
{'lender_id': 'matt',
'loan_count': 23,
'status': [2, 1, 3],
'sponsored': False,
'sponsor_name': None,
'lender_dem': {'sex': 'm', 'age': 77}}
The dictionary matches the format of the Kiva file. This format doesn’t naturally translate to a data frame. The json_normalize method can organize this semistructured JSON data into a flat table:
ex_df = pd.json_normalize(ex_dict)
ex_df
| lender_id | loan_count | status | sponsored | sponsor_name | lender_dem.sex | lender_dem.age | |
|---|---|---|---|---|---|---|---|
| 0 | matt | 23 | [2, 1, 3] | False | None | m | 77 |
Notice how the third element in this one-row data frame is a list, whereas, the nested object was converted into two columns.
There’s a tremendous amount of flexibility in how data can be structured in JSON, which means that if we want to create a data frame from JSON content, we need to understand how the data are organized in the JSON file. We provide three structures that translate easily into a data frame in the next example.
The list of PurpleAir sites used in the case study in Chapter 12 was JSON formatted. In that chapter, we didn’t call attention to the format and simply read the file contents into a dictionary with the json library’s load method and then into a data frame. Here, we have simplified that file while maintaining the general structure so that it’s easier to examine.
We begin with an examination of the original file, and then reorganize it into two other JSON structures that might also be used to represent a data frame. With these examples we aim to show the flexibility of JSON. The diagrams in Figure 14.2 give representations of the three possibilities.
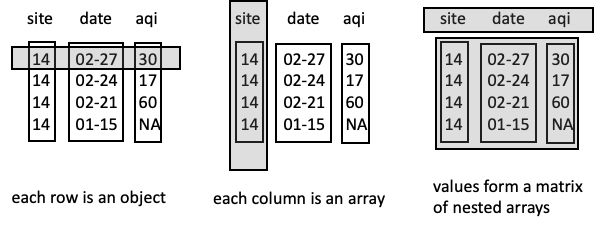
Fig. 14.2 Three different approaches for a JSON-formatted to store a dataframe#
The leftmost data frame in the diagram shows an organization by rows. Each row is an object of named values where the name corresponds to the column name of the data frame. Rows would then be collected in an array. This structure coincides with that of the original file. In the following code, we display the file contents:
{"Header": [
{"status": "Success",
"request_time": "2022-12-29T01:48:30-05:00",
"url": "https://aqs.epa.gov/data/api/dailyData/...",
"rows": 4
}
],
"Data": [
{"site": "0014", "date": "02-27", "aqi": 30},
{"site": "0014", "date": "02-24", "aqi": 17},
{"site": "0014", "date": "02-21", "aqi": 60},
{"site": "0014", "date": "01-15", "aqi": null}
]
}
We see that the file consists of one object with two elements, named Header and Data. The Data element is an array with an element for each row in the data frame, and as described earlier each element is an object. Let’s load the file into a dictionary and check its contents (see Chapter 8 for more on finding a pathname to a file and printing its contents):
from pathlib import Path
import os
epa_file_path = Path('data/js_ex/epa_row.json')
data_row = json.loads(epa_file_path.read_text())
data_row
{'Header': [{'status': 'Success',
'request_time': '2022-12-29T01:48:30-05:00',
'url': 'https://aqs.epa.gov/data/api/dailyData/...',
'rows': 4}],
'Data': [{'site': '0014', 'date': '02-27', 'aqi': 30},
{'site': '0014', 'date': '02-24', 'aqi': 17},
{'site': '0014', 'date': '02-21', 'aqi': 60},
{'site': '0014', 'date': '01-15', 'aqi': None}]}
We can quickly convert the array of objects into a data frame with the following call:
pd.DataFrame(data_row["Data"])
| site | date | aqi | |
|---|---|---|---|
| 0 | 0014 | 02-27 | 30.0 |
| 1 | 0014 | 02-24 | 17.0 |
| 2 | 0014 | 02-21 | 60.0 |
| 3 | 0014 | 01-15 | NaN |
The middle diagram in Figure 14.2 takes a column approach to organizing the data. Here the columns are provided as arrays and collected into an object with names that match the column names. The following file demonstrates the concept:
epa_col_path = Path('data/js_ex/epa_col.json')
print(epa_col_path.read_text())
{"site":[ "0014", "0014", "0014", "0014"],
"date":["02-27", "02-24", "02-21", "01-15"],
"aqi":[30,17,60,null]}
Since pd.read_json() expects this format, we can read the file into a
dataframe directly without needing to first load it into a dictionary:
pd.read_json(epa_col_path)
| site | date | aqi | |
|---|---|---|---|
| 0 | 14 | 02-27 | 30.0 |
| 1 | 14 | 02-24 | 17.0 |
| 2 | 14 | 02-21 | 60.0 |
| 3 | 14 | 01-15 | NaN |
Lastly, we organize the data into a structure that resembles a matrix (the diagram on the right in the figure) and separately provide the column names for the features. The data matrix is organized as an array of arrays:
epa_mat_path = Path('data/js_ex/epa_val.json')
data_mat = json.loads(epa_mat_path.read_text())
data_mat
{'vars': ['site', 'date', 'aqi'],
'data': [['0014', '02-27', 30],
['0014', '02-24', 17],
['0014', '02-21', 60],
['0014', '01-15', None]]}
We can provide vars and data to create the data frame:
pd.DataFrame(data_mat["data"], columns=data_mat["vars"])
| site | date | aqi | |
|---|---|---|---|
| 0 | 0014 | 02-27 | 30.0 |
| 1 | 0014 | 02-24 | 17.0 |
| 2 | 0014 | 02-21 | 60.0 |
| 3 | 0014 | 01-15 | NaN |
We’ve included these examples to show the versatility of JSON. The main takeaway is that JSON files can arrange data in different ways, so we typically need to examine the file before we can read the data into a data frame successfully. JSON files are very common for data stored on the web: the examples in this section were files downloaded from the PurpleAir and Kiva websites. Although we downloaded the data manually in this section, we often want to download many datafiles at a time, or we want a reliable and reproducible record of the download. In the next section, we introduce HTTP, a protocol that will let us write programs to download data from the web automatically.