XML, HTML, and XPath
Contents
14.5. XML, HTML, and XPath#
The eXtensible Markup Language (XML ) can represent all types of information, such as data sent to and from web services, including web pages, spreadsheets, visual displays like SVG, social network structures, word processing documents like MicroSoft’s docx, databases, and much more. For a data scientist, knowing a little about XML can come in handy.
Despite its name, XML is not a language. Rather, it is a very general structure we can use to define formats to represent and organize data. XML provides a basic structure and syntax for these “dialects” or vocabularies. If you read or composed HTML, you will recognize the format of XML.
The basic unit in XML is the element, which is also referred to as a node. An element has a name and may have attributes, child elements, and text. The following annotated snippet of an XML plant catalog provides an example of these pieces (this content is adapted from W3Schools):
<catalog> The topmost node, aka root node.
<plant> The first child of the root node.
<common>Bloodroot</common> common is the first child of plant.
<botanical>Sanguinaria canadensis</botanical>
<zone>4</zone> This zone node has text content: 4.
<light>Mostly Shady</light>
<price curr="USD">$2.44</price> This node has an attribute.
<availability date="0399"/> Empty nodes can be collapsed.
</plant> Nodes must be closed.
<plant> The two plant nodes are siblings.
<common>Columbine</common>
<botanical>Aquilegia canadensis</botanical>
<zone>3</zone>
<light>Mostly Shady</light>
<price curr="CAD">$9.37</price>
<availability date="0199"/>
</plant>
</catalog>
We added the indentation to this snippet of XML to make it easier to see the structure. It is not needed in the actual file.
XML documents are plain-text files with the following syntax rules:
Each element begins with a start tag, like `<plant>
, and closes with an end tag of the same name, like \</plant>`.XML elements can contain other XML elements.
XML elements can be plain-text, like “Columbine” in `<common>Columbine</common>`.
XML elements can have optional attributes. The element <price curr=“CAD”> has an attribute
currwith value"CAD".In the special case when a node has no children, the end tag can be folded into the start tag. An example is `
`.
We call an XML document well formed when it follows certain rules. The most important of these are:
One root node contains all of the other elements in the document.
Elements nest properly; an open node closes around all of its children and no more.
Tag names are case sensitive.
Attribute values have a name=“value” format with single or double quotes.
There are additional rules for a document to be well formed. These relate to whitespace, special characters, naming conventions, and repeated attributes.
The hierarchical nature of well-formed XML means it can be represented as a tree. Figure 14.4 shows a tree representation of the plant catalog XML.
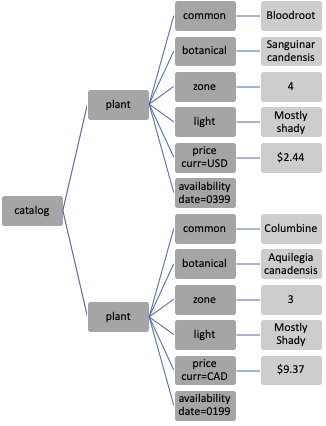
Fig. 14.4 Hierarchy of an XML document; the lighter gray boxes represent text elements and, by design, these cannot have child nodes#
Like with JSON, an XML document is plain-text. We can read it with a plain-text viewer, and it’s easy for machines to read and create XML content. The extensible nature of XML allows content to be easily merged into higher-level container documents and easily exchanged with other applications. XML also supports binary data and arbitrary character sets.
As mentioned already, HTML looks a lot like XML. That’s no accident, and indeed, XHTML is a subset of HTML that follows the rules of well-formed XML. Let’s return to our earlier example of the Wikipedia page that we retrieved from the internet and show how to used XML tools to create a data frame from the contents of one of its tables.
14.5.1. Example: Scraping Race Times from Wikipedia#
Earlier in this chapter, we used an HTTP request to retrieve the HTML page from Wikipedia shown in Figure 14.3. The contents of this page are in HTML, which is essentially an XML vocabulary. We can use the hierarchical structure of the page and XML tools to access data in one of the tables and wrangle it into a data frame. In particular, we are interested in the second table in the page, a portion of which appears in the screenshot in Figure 14.5.
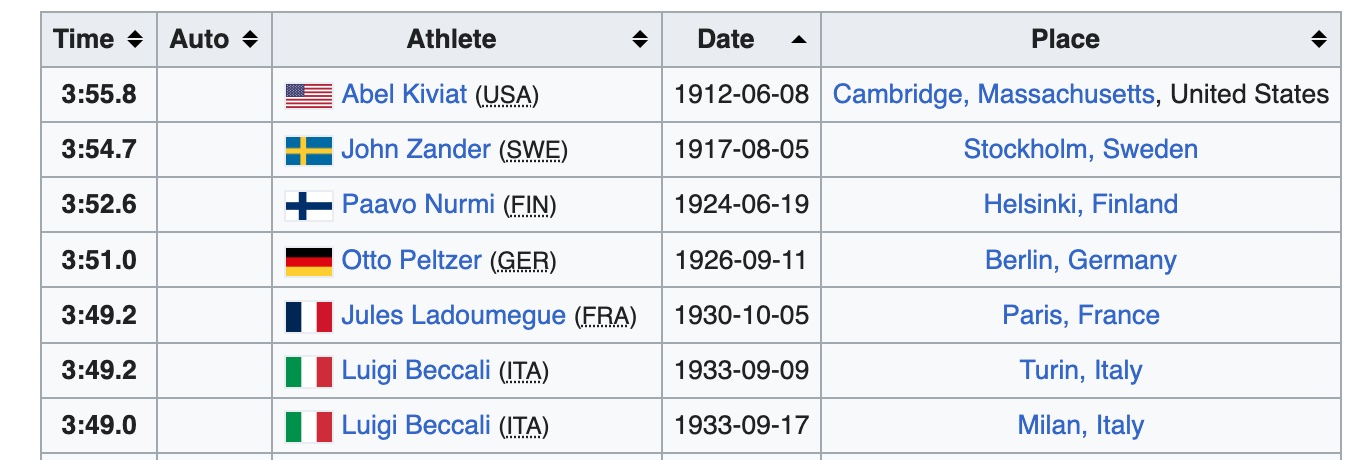
Fig. 14.5 Screenshot of the second table in a web page that contains the data we want to extract#
Before we work on this table, we provide a quick summary of the format for a basic HTML table. Here is the HTML for a table with a header and two rows of three columns:
<table>
<tbody>
<tr>
<th>A</th><th>B</th><th>C</th>
</tr>
<tr>
<td>1</td><td>2</td><td>3</td>
</tr>
<tr>
<td>5</td><td>6</td><td>7</td>
</tr>
</tbody>
</table>
Notice how the table is laid out in rows with `<tr> elements, and each cell in a row is a \<td>` element that contains the text to be displayed in the table.
Our first task is to create a tree structure from the content of the web page. To do this, we use the lxml library, which provides access to the C-library libxml2 for handling XML content. Recall that resp_1500 contains the response from our request, and the page is in the body of the response. We can parse the web page into a hierarchical structure with fromstring in the lxml.html module:
from lxml import html
tree_1500 = html.fromstring(resp_1500.content)
type(tree_1500)
lxml.html.HtmlElement
Now we can work with the document using its tree structure. We can find all the tables in the HTML document with the following search:
tables = tree_1500.xpath('//table')
type(tables)
list
len(tables)
7
This search uses the XPath //table expression, which we soon describe, to search for all table nodes anywhere in the document.
We found six tables in the document. If we examine the web page, including looking at its HTML source via the browser, we can figure out that the second table in the document contains the IAF-era times. This is the table we want. The screenshot in Figure 14.5 shows that the first column contains the race times, the third holds names, and the fourth has the dates of the races. We can extract each of these pieces of information in turn. We do this with the following XPath expressions:
times = tree_1500.xpath('//table[3]/tbody/tr/td[1]/b/text()')
names = tree_1500.xpath('//table[3]/tbody/tr/td[3]/a/text()')
dates = tree_1500.xpath('//table[3]/tbody/tr/td[4]/text()')
type(times[0])
lxml.etree._ElementUnicodeResult
These return values behave like a list, but each value is an element of the tree. We can convert them to strings:
date_str = [str(s) for s in dates]
name_str = [str(s) for s in names]
For the times, we want to transform them into seconds. The function get_sec does this conversion. And we want to extract the race year from the date string:
def get_sec(time):
"""convert time into seconds."""
time = str(time)
time = time.replace("+","")
m, s = time.split(':')
return float(m) * 60 + float(s)
time_sec = [get_sec(rt) for rt in times]
race_year = pd.to_datetime(date_str, format='%Y-%m-%d\n').year
men_1500 = pd.DataFrame({"race_time":time_sec, "athlete":name_str,
"year":race_year})
men_1500
| race_time | athlete | year | |
|---|---|---|---|
| 0 | 235.80 | Abel Kiviat | 1912 |
| 1 | 234.70 | John Zander | 1917 |
| 2 | 232.60 | Paavo Nurmi | 1924 |
| ... | ... | ... | ... |
| 35 | 208.86 | Noureddine Morceli | 1992 |
| 36 | 207.37 | Noureddine Morceli | 1995 |
| 37 | 206.00 | Hicham El Guerrouj | 1998 |
38 rows × 3 columns
We can create a data frame and make a plot to show the progress in race times over the years:
px.scatter(men_1500, x='year', y='race_time',
labels={'year':'Year', 'race_time':'Time (sec)'},
width=450, height=250)

As you may have noticed, extracting data from an HTML page relies on careful examination of the source to find where in the document are the numbers that we’re after. We relied heavily on the XPath tool to do the extraction. Its elegant language is quite powerful. We introduce it next.
14.5.2. XPath#
When we work with XML documents, we typically want to extract data from them and bring it into a data frame. XPath can help here. XPath can recursively traverse an XML tree to find elements. For example, we used the expression //table in the previous example to locate all table nodes in our web page.
XPath expressions operate on the hierarchy of well-formed XML. They are succinct and similar in format to the way files are located in a hierarchy of directories in a computer filesystem. But they’re much more powerful. XPath is also similar to regular expressions in that we specify patterns to match content. Like with regular expressions, it takes experience to compose correct XPath expressions.
An XPath expression forms logical steps to identify and filter nodes in a tree. The result is a node set where each node occurs at most once. The node set also has an order that matches the order in which the nodes occur in the source; this can be quite handy.
Each XPath expression is made up of one or more location steps, separated by a “/”. Each location step has three parts—the axis, node test, and optional predicate:
The axis specifies the direction to look in, such as down, up, or across the tree. We exclusively use shortcuts for the axis. The default is to look down one step at children in the tree.
//says to look down the tree as far as possible, and..indicates one step up to the parent.The node test identifies the name or the type of node to look for. This is typically just a tag name or
text()for text elements.A predicate acts like a filter to further restrict the node set. These are given in square brackets, like
[2], which keeps the second node in the node set, and[ @date ], which keeps all nodes with a date attribute.
We can tack together location steps to create powerful search instructions. Table 14.2 provides some examples that cover the most common expressions. Refer back to the tree in Figure 14.4 to follow along.
Expression |
Result |
Description |
|---|---|---|
‘//common’ |
Two nodes |
Look down the tree for any common nodes. |
‘/catalog/plant/common’ |
Two nodes |
Travel the specific path from the root node catalog to all plant nodes to all common nodes within the plant nodes. |
‘//common/text()’ |
Bloodroot, Columbine |
Locate the text content of all common nodes. |
‘//plant[2]/price/text()’ |
$9.37 |
Locate plant nodes anywhere in the tree, then filter to take only the second. From this plant node, travel to its price child and locate its text. |
‘//@date’ |
0399, 0199 |
Locate the attribute value of any attribute named “date” in the tree. |
‘//price[@curr=“CAD”]/text()’ |
$9.37 |
The text content of any price node that has a currency attribute value of “CAD.” |
You can try out the XPath expressions in the table with the catalog file. We load the file into Python using the etree module. The parse method reads the file into an element tree:
from lxml import etree
catalog = etree.parse('data/catalog.xml')
The lxml library gives us access to XPath. Let’s try it out.
Here is a simple XPath expression to locate all text content of any <light> node in the tree:
catalog.xpath('//light/text()')
['Mostly Shady', 'Mostly Shady']
Notice that two elements are returned. Although the text content is identical, we have two <light> nodes in our tree and so are given the text content of each. The following expression is a bit more challenging:
catalog.xpath('//price[@curr="CAD"]/../common/text()')
['Columbine']
The expression locates all <price> nodes in the tree, then filters them according to whether their curr attribute is CAD. Then, for the remaining nodes (there’s only one in this case), travel up one step in the tree to the parent node and then back down to any child “common” nodes and on to their text content. Quite the trip!
Next, we provide an example that uses an HTTP request to retrieve XML-formatted data, and XPath to wrangle the content into a data frame.
14.5.3. Example: Accessing Exchange Rates from the ECB#
The European Central Bank (ECB) makes exchange rates available online in an XML format. Let’s begin by getting the most recent exchange rates from the ECB with an HTTP request:
url_base = 'https://www.ecb.europa.eu/stats/eurofxref/'
url2 = 'eurofxref-hist-90d.xml?d574942462c9e687c3235ce020466aae'
resECB = requests.get(url_base+url2)
resECB.status_code
200
Again, we can use the lxml library to parse the text document we received from the ECB, but this time the contents are in a string returned to us from the ECB, not in a file:
ecb_tree = etree.fromstring(resECB.content)
In order to extract the data we want, we need to know how it is organized. Here is a snippet of the content:
<gesmes:Envelope xmlns:gesmes="http://www.gesmes.org/xml/2002-08-01"
xmlns="http://www.ecb.int/vocabulary/2002-08-01/eurofxref">
<gesmes:subject>Reference rates</gesmes:subject>
<gesmes:Sender>
<gesmes:name>European Central Bank</gesmes:name>
</gesmes:Sender>
<Cube>
<Cube time="2023-02-24">
<Cube currency="USD" rate="1.057"/>
<Cube currency="JPY" rate="143.55"/>
<Cube currency="BGN" rate="1.9558"/>
</Cube>
<Cube time="2023-02-23">
<Cube currency="USD" rate="1.0616"/>
<Cube currency="JPY" rate="143.32"/>
<Cube currency="BGN" rate="1.9558"/>
</Cube>
</Cube>
</gesmes:Envelope>
This document appears quite different in structure from the plant catalog. The snippet shows three levels of tags, all with the same name, and none have text content. All of the relevant information is contained in attribute values. Other new features are the xmlns in the root <Envelope> node, and the odd tag names, like gesmes:Envelope. These have to do with namespaces.
XML allows content creators to use their own vocabularies, called namespaces. The namespace gives the rules for a vocabulary, such as allowable tag names and attribute names, and restrictions on how nodes can be nested. And XML documents can merge vocabularies from different applications. To keep it all straight, information about the namespace(s) is provided in the document.
The root node in the ECB file is <Envelope>. The additional “gesmes:” in the tag name indicates that the tags belong to the gesmes vocabulary, which is an international standard for the exchange of time-series information. Another namespace is also in <Envelope>. It is the default namespace for the file because it doesn’t have a prefix, like “gesmes:”. Whenever a namespace is not provided in a tag name, the default is assumed.
The upshot of this is that we need to take into account these namespaces when we search for nodes. Let’s see how this works when we extract the dates. From the snippet, we see that the dates reside in “time” attributes. These <Cube>s are children of the top <Cube>. We can give a very specific XPath expression to step from the root to its <Cube> child node and on to the next level of <Cube> nodes:
namespaceURI = 'http://www.ecb.int/vocabulary/2002-08-01/eurofxref'
date = ecb_tree.xpath('./x:Cube/x:Cube/@time', namespaces = {'x':namespaceURI})
date[:5]
['2023-07-18', '2023-07-17', '2023-07-14', '2023-07-13', '2023-07-12']
The . in the expression is a shortcut to signify “from here,” and since we’re at the top of the tree, it’s equivalent to “from the root.” We specified the namespace in our expression as “x:”. Even though the <Cube> nodes are using the default namespace, we must specify it in our XPath expression. Fortunately, we can simply pass in the namespace as a parameter with our own label (“x” in this case) to keep our tag names short.
Like with the HTML table, we can convert the date values into strings and from strings into timestamps:
date_str = [str(s) for s in date]
timestamps = pd.to_datetime(date_str)
xrates = pd.DataFrame({"date":timestamps})
As for the exchange rates, they also appear in <Cube> nodes, but these have a “rate” attribute. For example, we can access all exchange rates for the British pound with the following XPath expression (we’re ignoring the namespace for the moment):
//Cube[@currency = "GBP"]/@rate
This expression says look for all <Cube> nodes anywhere in the document, filter them according to whether the node has a currency attribute value of “GBP”, and return their rate attribute values.
Since we want to extract exchange rates for multiple currencies, we generalize this XPath expression. We also want to convert the exchange rates to a numeric storage type, and make them relative to the first day’s rate so that the different currencies are on the same scale, which makes them more amenable for plots:
currs = ['GBP', 'USD', 'CAD']
for ctry in currs:
expr = './/x:Cube[@currency = "' + ctry + '"]/@rate'
rates = ecb_tree.xpath(expr, namespaces = {'x':namespaceURI})
rates_num = [float(rate) for rate in rates]
first = rates_num[len(rates_num)-1]
xrates[ctry] = [rate / first for rate in rates_num]
xrates.head()
| date | GBP | USD | CAD | |
|---|---|---|---|---|
| 0 | 2023-07-18 | 0.97 | 1.03 | 1.01 |
| 1 | 2023-07-17 | 0.97 | 1.03 | 1.01 |
| 2 | 2023-07-14 | 0.97 | 1.03 | 1.00 |
| 3 | 2023-07-13 | 0.97 | 1.02 | 1.00 |
| 4 | 2023-07-12 | 0.97 | 1.01 | 0.99 |
We wrap up this example with line plots of the exchange rates:
fig = px.line(xrates, x='date', y=["USD", "CAD", "GBP"],
line_dash='variable',
title="Exchange rate with the euro",
width=650, height=300)
fig.update_xaxes(title=None)
fig.update_yaxes(title='Exchange rate relative to first day')
fig.update_layout(legend_title_text='Currency', margin=dict(t=30))
fig.show()

Combining knowledge of JSON, HTTP, REST, and HTML gives us access to a vast variety of data available on the web. For example, in this section we wrote code to scrape data from a Wikipedia page. One key advantage of this approach is that we can likely rerun this code in a few months to automatically update the data and the plots. One key drawback is that our approach is tightly coupled to the structure of the web page—if someone updates the Wikipedia page and the table is no longer the second table on the page, our code will also need some edits in order to work. That said, having the skills needed to scrape data from the web opens the door to a wide range of data and enables all kinds of useful analyses.