Quality Checks
Contents
9.2. Quality Checks#
Once your data are in a table and you understand the scope and granularity, it’s time to inspect for quality. You may have come across errors in the source as you examined and wrangled the file into a dataframe. In this section, we describe how to continue this inspection and carry out a more comprehensive assessment of the quality of the features and their values. We consider data quality from four vantage points:
- Scope
Do the data match your understanding of the population?
- Measurements and values
Are the values reasonable?
- Relationships
Are related features in agreement?
- Analysis
Which features might be useful in a future analysis?
We describe each of these points in turn, beginning with scope.
9.2.1. Quality Based on Scope#
In Chapter 2, we addressed whether or not the data that have been collected can adequately address the problem at hand. There, we identified the target population, access frame, and sample in collecting the data. That framework helps us consider possible limitations that might impact the generalizability of our findings.
While these broader data-scope considerations are important as we deliberate our final conclusions, they are also useful for checking data quality. For example, for the San Francisco restaurant inspections data introduced in Chapter 8, a side investigation tells us that zip codes in the city should start with 941. But a quick check shows that several zip codes begin with other digits:
bus['postal_code'].value_counts().tail(10)
92672 1
64110 1
94120 1
..
94621 1
941033148 1
941 1
Name: postal_code, Length: 10, dtype: int64
This verification using scope helps us spot potential problems.
As another example, a bit of background reading at Climate.gov and NOAA on the topic of atmospheric CO2 reveals that typical measurements are about 400 ppm worldwide. So we can check whether the monthly averages of CO2 at Mauna Loa lie between 300 and 450 ppm.
Next, we check data values against codebooks and the like.
9.2.2. Quality of Measurements and Recorded Values#
We can use also check the quality of measurements by considering what might be a reasonable value for a feature. For example, imagine what might be a reasonable range for the number of violations in a restaurant inspection: possibly, 0 to 5. Other checks can be based on common knowledge of ranges: a restaurant inspection score must be between 0 and 100; months run between 1 and 12. We can use documentation to tell us the expected values for a feature. For example, the type of emergency room visit in the DAWN survey, introduced in Chapter 8, has been coded as 1, 2, …, 8 (see Figure 9.1). So we can confirm that all values for the type of visit are indeed integers between 1 and 8.
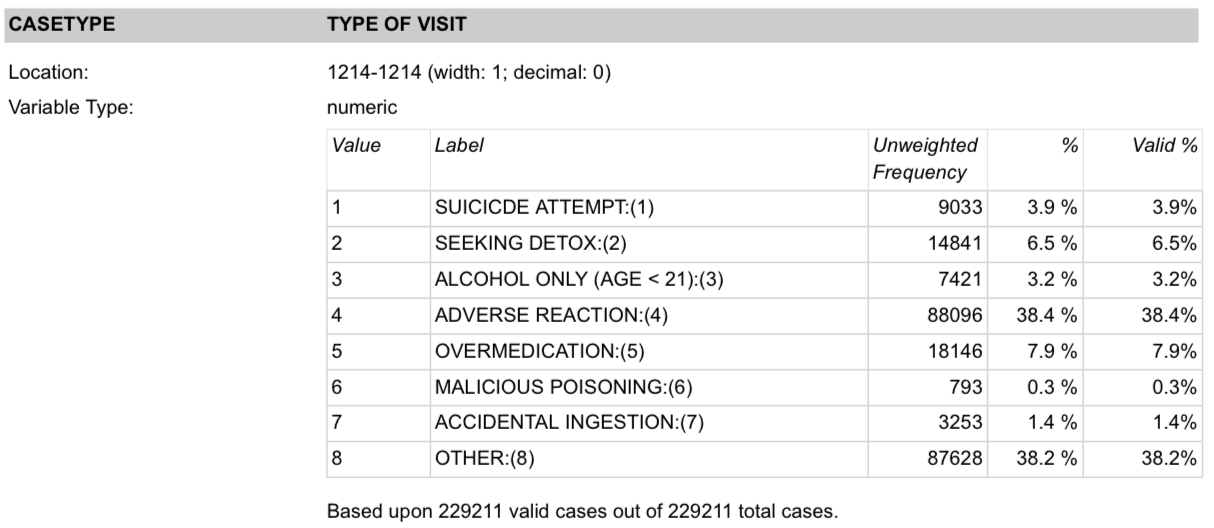
Fig. 9.1 Screenshot of the description of the emergency room visit type (CASETYPE) variable in the DAWN survey (the typo SUICICDE appears in the actual codebook)#
We also want to ensure that the data type matches our expectations. For example, we expect a price to be a number, whether or not it’s stored as integer, floating point, or string. Confirming that the units of measurement match what is expected can be another useful quality check to perform (for example, weight values recorded in pounds, not kilograms). We can devise checks for all of these situations.
Other checks can be devised by comparing two related features.
9.2.4. Quality for Analysis#
Even when data pass the previous quality checks, problems can arise with its usefulness. For example, if all but a handful of values for a feature are identical, then that feature adds little to the understanding of underlying patterns and relationships. Or if there are too many missing values, especially if there is a discernible pattern in the missing values, our findings may be limited. Plus, if a feature has many bad/corrupted values, then we might question the accuracy of even those values that fall in the appropriate range.
We see in the following code that the type of restaurant inspection in San Francisco can be either routine or from a complaint. Since only one of the 14,000+ inspections was from a complaint, we lose little if we drop this feature, and we might also want to drop that single inspection since it represents an anomaly:
pd.value_counts(insp['type'])
routine 14221
complaint 1
Name: type, dtype: int64
Once we find problems with our data, we need to figure out what to do.
9.2.5. Fixing the Data or Not#
When you uncover problems with the data, essentially you have four options: leave the data as is; modify values; remove features; or drop records.
- Leave it as is
Not every unusual aspect of the data needs to be fixed. You might have discovered a characteristic of your data that will inform you about how to do your analysis and otherwise does not need correcting. Or you might find that the problem is relatively minor and most likely will not impact your analysis, so you can leave the data as is. Or, you might want to replace corrupted values with
NaN.- Modify individual values
If you have figured out what went wrong and can correct the value, then you can opt to change it. In this case, it’s a good practice to create a new feature with the modified value and preserve the original feature, like in the CO2 example.
- Remove a column
If many values in a feature have problems, then consider eliminating that feature entirely. Rather than exclude a feature, there may be a transformation that allows you to keep the feature while reducing the level of detail recorded.
- Drop records
In general, we do not want to drop a large number of observations from a dataset without good reason. Instead, try to scale back your investigation to a particular subgroup of the data that is clearly defined by some criteria, and does not simply correspond dropping records with corrupted values. When you discover that an unusual value is in fact correct, you still might decide to exclude the record from your analysis because it’s so different from the rest of your data and you do not want it to overly influence your analysis.
Whatever approach you take, you will want to study the possible impact of the changes that you make on your analysis. For example, try to determine whether the records with corrupted values are similar to one another, and different from the rest of the data.
Quality checks can reveal issues in the data that need to be addressed before proceeding with analysis.
One particularly important type of check is to look for missing values. We suggested
that there may be times when you want to replace corrupted data values with
NaN, and hence treat them as missing. At other times, data might arrive
missing. What to do with missing data is an important topic, and there is a lot
of research on this problem; we cover ways to address missing data in the next section.